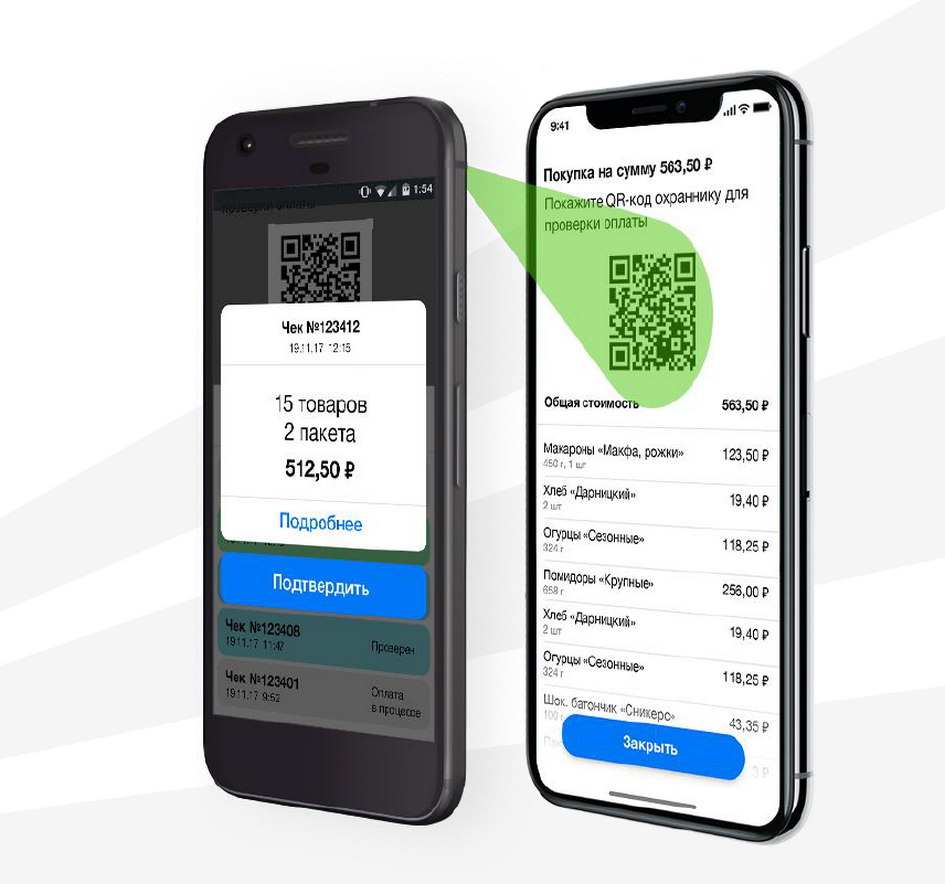
Аналитика вещей
Материалы подготовлены редакцией партнерских проектов РБК+.
Автор: Наталья Кисилева

Фото: Bloomberg
Технологии Big Data не самоцель — бизнесу нужна практическая польза от аналитики и понятная монетизация данных. Новый импульс этому рынку даст формирующийся повсеместно интернет вещей (Internet of Things, IoT).
Рынок технологий Big Data, с одной стороны, бурно развивается, демонстрируя ежегодный рост на 10–12% во всем мире — на фоне общего спада отрасли IT. С другой стороны, он несколько буксует в силу сложности и длительности проектов, неочевидности отдачи от них и извлекаемой из больших данных ценности. Сами по себе решения Big Data не дают бизнесу моментальных преимуществ. В результате многие компании если не притормаживают, то и не спешат запускать масштабные новые инициативы.
По данным международной аналитической компании Gartner, 48% опрошенных предприятий инвестировали в Big Data в 2016 году на 3% меньше, чем в 2015-м. Доля тех, кто планирует такие проекты в следующую пару лет, снизилась с 31 до 25%. Аналитики поясняют, что проблема — в поиске оптимальных сценариев использования больших данных для решения конкретных бизнес-задач. Отмечается, что многие инициативы так и не развиваются далее пилотных проектов, а значит, не окупаются.
«Технологии Big Data и связанных с ними Machine Learning (машинное обучение) наиболее эффективно проявят себя там, где огромные потоки данных необходимо обрабатывать онлайн для предоставления клиенту нужного продукта «здесь и сейчас», как в телекоме, финансах, рекламе, e-commerce, — комментирует Валерий Никитин, технический директор IT-компании «Техносерв». — Либо там, где накоплены значительные массивы информации, постоянный анализ которых позволяет выявлять скрытые взаимосвязи, находить факты и новые области применения существующих знаний. Примером является промышленная безопасность и надежность, когда новые технологии позволяют более точно оценить необходимость остановки агрегатов для ремонта и сэкономить на увеличении срока эксплуатации и снижения простоев».
Наиболее часто реализуются сегодня проекты в области клиентской аналитики и борьбы с мошенничеством, которые окупаются в течение года или даже быстрее за счет увеличения продаж, сокращения оттока или же предотвращения убытков от мошенничества, отмечают в провайдере решений в области бизнес-анализа SAS.
Умная обработка
Исследования с большими данными эволюционируют в сторону все более сложных моделей, увеличивая кадровый дефицит аналитиков-математиков или data scientists.
«Как следствие, все больший объем интеллектуальной работы по обработке информации, выявлению корреляций, отклонений от типового поведения и т.п. будет брать на себя искусственный интеллект, — считает Юлий Гольдберг, директор по инновациям SAS Россия/СНГ. — Уже возобновились разговоры о программируемых организациях, в которых значительная часть внутренних процессов будет не только автоматизирована при помощи компьютеров, но и будет управляться при помощи сложных и самообучаемых алгоритмов». Например, рекомендательные системы интернет-магазинов уходят от простых и малоэффективных правил подбора оптимального предложения к применению сложных моделей, разрабатываемых и подстраиваемых в перманентном режиме системой machine learning, поясняют в SAS.
Искусственный интеллект (ИИ) становится новой «большой идеей» — в мире инвестиции в него превышают $500 млн. По прогнозам международной исследовательской компании Markets and Markets, к 2020 году рынок ИИ вырастет до $5 млрд за счет применения технологий машинного обучения и распознавания естественного языка в рекламе, розничной торговле, финансах и здравоохранении.
В Gartner считают, что к 2020 году около 40% всех взаимодействий с виртуальными помощниками будет опираться на данные, обработанные нейронными сетями. По ожиданиям аналитической компании Forrester, в следующие десять лет искусственный интеллект заменит до 16% всех рабочих мест в США.
Подключенные источники
Новая волна ожиданий в связи с Big Data ассоциируется с распространением технологий интернета вещей. Аналитика в режиме реального времени позволит обрабатывать потоковую информацию, которую будут генерировать устройства, взаимодействуя друг с другом или с внешней средой.

По прогнозам аналитического центра McKinsey Global Institute, вклад интернета вещей в глобальную экономику к 2025 году составит до $11 трлн. Именно подключенные устройства, количество которых, предположительно, превысит к тому моменту 100 млрд единиц во всем мире (и 500 млн — в России), будут создавать гигантские массивы данных. Они потребуют новых подходов как к обработке и анализу, так и к хранению с учетом максимально возможного снижения его стоимости.
Для бизнеса интернет вещей обещает повышение производительности, а также снижение эксплуатационных расходов и других издержек. В первую очередь в этих технологиях заинтересованы промышленные предприятия с распределенными активами. IoT поможет эффективнее управлять ими, осуществляя мониторинг состояния объектов и оборудования, чтобы предотвращать поломки и оперативно реагировать на инциденты.
Эти же подходы будут применять и поставщики промышленного оборудования — в том числе лифтового. Так, немецкий концерн Thyssen Krupp Elevator уже перестроил бизнес-процессы и организовал профилактическое обслуживание лифтов на основе прогнозирования поломок. С помощью сервисов машинного обучения и интернета вещей из облака Microsoft Azure была создана единая система самодиагностики, которая обеспечила бесперебойную работу подъемных машин.
«Реальное проникновение IoT в потребительский сегмент привело к появлению огромных пластов новых и крайне интересных для анализа данных, — рассказывает Юлий Гольдберг. — Электрические зубные щетки с Bluetooth, передающие в облако данные о том, как, где и сколько человек чистят зубы, принимающие план чистки от зубного врача и контролирующие его выполнение. Электронные сигареты с Bluetooth, передающие информацию о количестве потребленного никотина и предупреждающие о необходимости сократить потребление для минимизации вреда. Дроны, которые летают над полями и собирают детальные данные о созревании урожая, нападениях вредителей, или датчики, собирающие информацию о состоянии почвы в разрезе отдельных участков полей, позволяют сделать интеллектуальным сельскохозяйственное производство. Не говоря уже о многочисленных смарт-часах и фитнес-трекерах, которые есть сегодня даже у детей, и передают в облако данные о геопозиции, пульсе, пройденных километрах, сожженных калориях, качестве сна и десятках других параметров. Обрабатывая эту информацию с помощью методов и инструментов Big Data, можно не просто эффективнее предлагать товары, но и помогать улучшать качество жизни людей».
Международная аналитическая компания IDC отмечает, что уже в этом году российские организации инвестируют более $4 млрд в интернет вещей, включая затраты на оборудование, программное обеспечение, услуги и связь. В течение 2016–2020 годов рынок IoT будет увеличиваться в среднем на 21% и к концу прогнозируемого периода составит $9 млрд. «Максимальный эффект от внедрения интернета вещей будет достигнут там, где он будет сочетаться с продвинутыми аналитическими сервисами и сервисами машинного обучения», — считает Владислав Шершульский, директор по перспективным технологиям Microsoft в России.